
1. SPA (Single Page Application)
단일 페이지 애플리케이션(Single Page Application, SPA)는 모던 웹의 패러다임이다. SPA는 기본적으로 단일 페이지로 구성되며 기존의 서버 사이드 렌더링과 비교할 때, 배포가 간단하며 네이티브 앱과 유사한 사용자 경험을 제공할 수 있다는 장점이 있다.
link tag를 사용하는 전통적인 화면 전환 방식은 새로운 페이지 요청 시마다 정적 리소스가 다운로드되고 전체 페이지를 다시 렌더링하는 방식을 사용하므로 새로고침이 발생되어 사용성이 좋지 않다. 그리고 변경이 필요없는 부분까지 포함하여 전체 페이지를 갱신하므로 비효율적이다.
SPA는 기본적으로 웹 애플리케이션에 필요한 모든 정적 리소스를 최초 접근시 단 한번만 다운로드한다. 이후 새로운 페이지 요청 시, 페이지 갱신에 필요한 데이터만을 JSON으로 전달받아 페이지를 갱신하므로 전체적인 트래픽을 감소시킬 수 있고, 전체 페이지를 다시 렌더링하지 않고 변경되는 부분만을 갱신하므로 새로고침이 발생하지 않아 네이티브 앱과 유사한 사용자 경험을 제공할 수 있다.
모바일 사용이 데스크톱을 넘어선 현재, 트래픽의 감소와 속도, 사용성, 반응성의 향상은 매우 중요한 이슈이다. SPA의 핵심 가치는 사용자 경험(UX) 향상에 있으며 부가적으로 애플리케이션 속도의 향상도 기대할 수 있어서 모바일 퍼스트(Mobile First) 전략에 부합한다.
모든 소프트웨어 아키텍처에는 트레이드오프(trade-off)가 존재하며 모든 애플리케이션에 적합한 은탄환(Silver bullet)은 없듯이 SPA 또한 구조적인 단점을 가지고 있다. 대표적인 단점은 다음과 같다.
- 초기 구동 속도
- SPA는 웹 애플리케이션에 필요한 모든 정적 리소스를 최초 접근시 단 한번 다운로드하기 때문에 초기 구동 속도가 상대적으로 느리다. 하지만 SPA는 웹페이지보다는 애플리케이션에 적합한 기술이므로 트래픽 감소와 속도, 사용성, 반응성의 향상 등의 장점을 생각한다면 결정적인 단점이라고 할 수는 없다.
- SEO(검색엔진 최적화) 이슈
- SPA는 일반적으로 서버 사이드 렌더링(SSR) 방식이 아닌 자바스크립트 기반 비동기 모델의 클라이언트 사이드 렌더링(CSR) 방식으로 동작한다. 클라이언트 사이드 렌더링(CSR)은 일반적으로 데이터 패치 요청을 통해 서버로부터 데이터를 응답받아 뷰를 동적으로 생성하는데 이때 브라우저 주소창의 URL이 변경되지 않는다. 이는 사용자 방문 history를 관리할 수 없음을 의미하며 SEO 이슈의 발생 원인이기도 하다. SPA의 SEO 이슈는 언제나 단점으로 부각되어 왔다. SPA는 정보 제공을 위한 웹페이지보다는 애플리케이션에 적합한 기술이므로 SEO 이슈는 심각한 문제로 취급할 수 없다고 생각할 수도 있지만 블로그와 같이 애플리케이션의 경우 SEO는 무시할 수 없는 중요한 의미를 갖는다. Angular나 React 등의 SPA 프레임워크는 서버 사이드 렌더링(SSR)을 지원하는 기능이 이미 존재하고 있고 크롬 등의 모던 브라우저는 SPA의 SEO 문제를 해결하고 있는 것으로 알려져 있다.
2. Routing
라우팅이란 출발지에서 목적지까지의 경로를 결정하는 기능이다. 애플리케이션의 라우팅은 사용자가 태스크를 수행하기 위해 어떤 화면(view)에서 다른 화면으로 화면을 전환하는 내비게이션을 관리하기 위한 기능을 의미한다. 일반적으로 라우팅은 사용자가 요청한 URL 또는 이벤트를 해석하고 새로운 페이지로 전환하기 위해 필요한 데이터를 서버에 요청하고 페이지를 전환하는 위한 일련의 행위를 말한다.
브라우저가 화면을 전환하는 경우는 다음과 같다.
-
브라우저의 주소창에 URL을 입력하면 해당 페이지로 이동한다.
-
웹페이지의 링크(a 태그)를 클릭하면 해당 페이지로 이동한다.
-
브라우저의 뒤로가기 또는 앞으로가기 버튼을 클릭하면 사용자 방문 기록(history)의 뒤 또는 앞으로 이동한다. history 관리를 위해서는 각 페이지는 브라우저의 주소창에서 구별할 수 있는 유일한 URL을 소유해야 한다.
3. SPA와 Routing
전통적인 링크 방식에서 SPA까지 발전하게 된 과정과 SPA의 라우팅(Routing)에 대해 살펴보도록 하자. 예제를 실행하기 위해 과정은 다음과 같다.
github에서 소스코드를 clone한다.
$ git clone https://github.com/ungmo2/spa-router.git
$ cd spa-router
$ npm install
예제의 실행 방법은 다음과 같다.
# 전통적 링크 방식
$ npm run link
# ajax 방식
$ npm run ajax
# hash 방식
$ npm run hash
# pjax(pushState + ajax) 방식
$ npm run pjax
3.1. 전통적 링크 방식
전통적 링크 방식은 link tag로 동작하는 기본적인 웹페이지의 동작 방식이다. 다음 코드를 살펴보자.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - Link</title>
<link rel="stylesheet" href="css/style.css" />
</head>
<body>
<nav>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/service.html">Service</a></li>
<li><a href="/about.html">About</a></li>
</ul>
</nav>
<section>
<h1>Home</h1>
<p>This is main page</p>
</section>
</body>
</html>
link tag(<a href="/service.html">Service</a> 등)을 클릭하면 href 어트리뷰트 값인 리소스 경로가 URL의 path에 추가되어 주소창에 나타나고 해당 리소스를 서버에 요청한다.
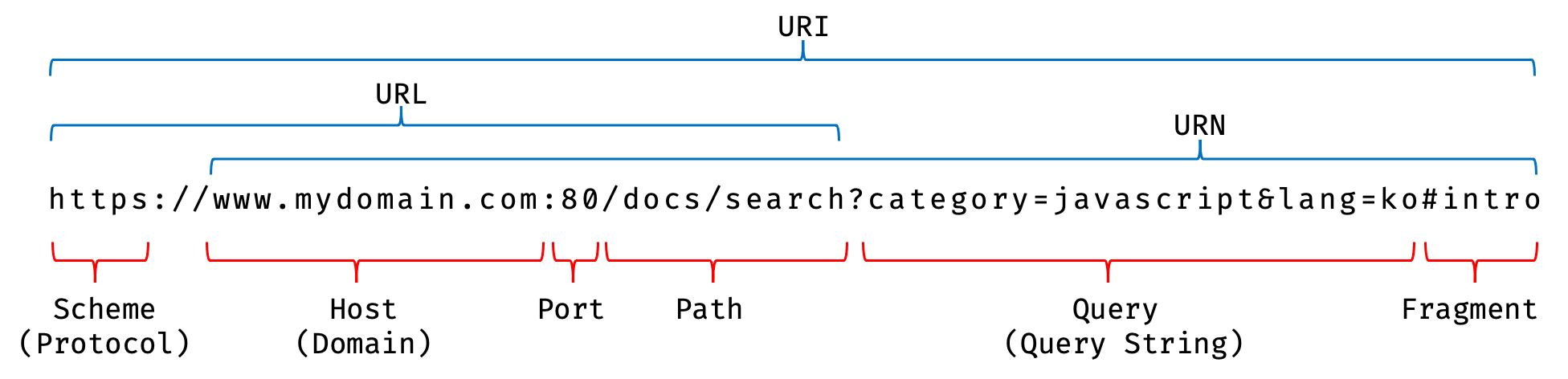
URI의 구조
이때 서버는 html로 화면을 표시하는데 부족함이 없는 완전한 리소스를 클라이언트에 응답한다. 이를 서버 사이드 렌더링(SSR)이라 한다. 브라우저는 서버가 응답한 html을 응답받아 렌더링한다. 이때 응답받은 html로 전체 페이지를 다시 렌더링하게 되므로 새로고침이 발생한다.
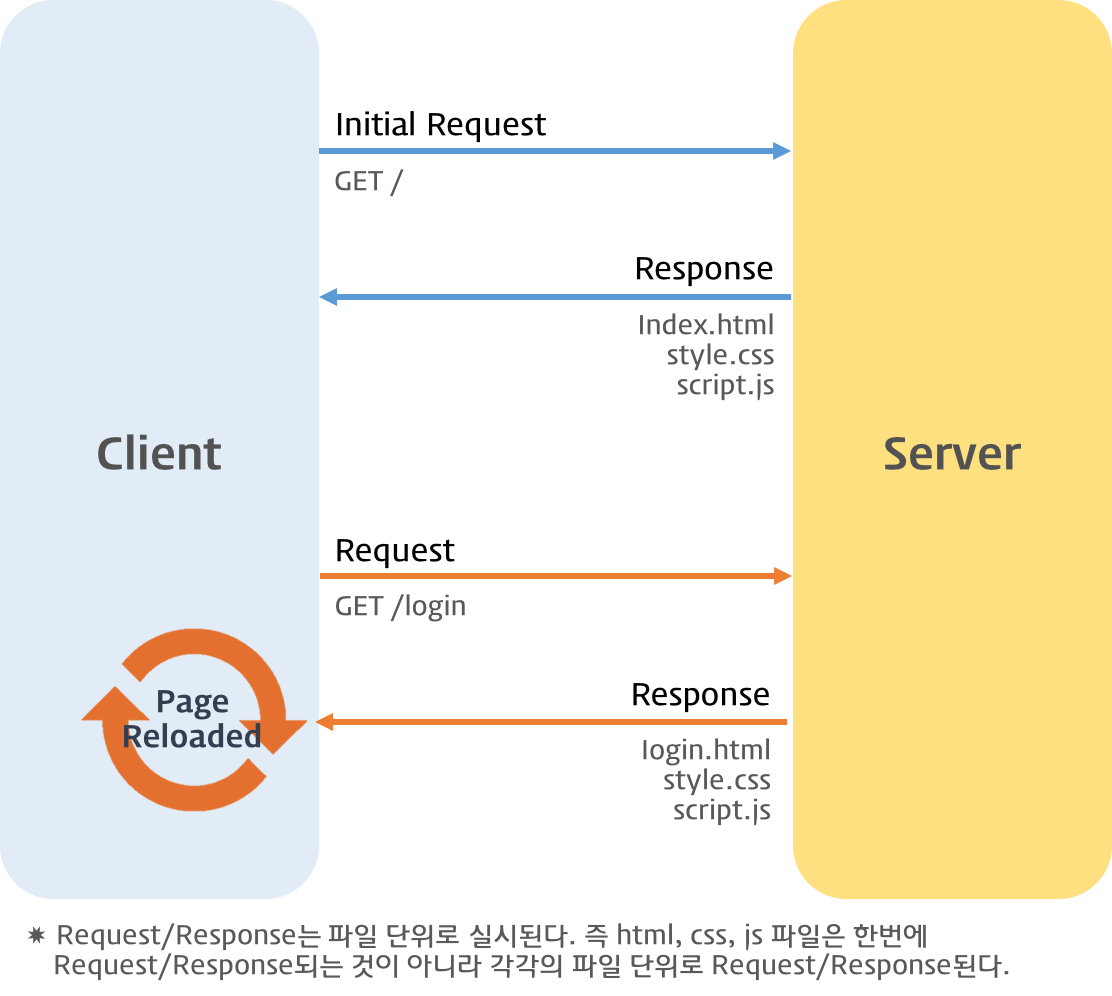
traditional webpage lifecycle
이 방식은 자바스크립트의 도움 없이 응답받은 html만으로 렌더링이 가능하며 각 페이지마다 고유의 URL이 존재하므로 history 관리 및 SEO 대응에 아무런 문제가 없다. 하지만 요청마다 중복된 리소스를 응답받아야 하며 전체 페이지를 다시 렌더링하는 과정에서 새로고침이 발생하여 사용성이 좋지 않은 단점이 있다.
위 예제를 실행하려면 다음 명령을 실행한다.
$ npm run link
3.2. ajax 방식
전통적 링크 방식은 현재 페이지에서 수신된 html로 화면을 전환하는 과정에서 전체 페이지를 새롭게 렌더링하게 되므로 새로고침이 발생한다. 간단한 웹페이지라면 문제될 것이 없겠지만 복잡한 웹페이지의 경우, 요청마다 중복된 HTML과 CSS, JavaScript를 매번 다운로드해야하므로 속도 저하의 요인이 된다.
전통적 링크 방식의 단점을 보완하기 위해 등장한 것이 ajax(Asynchronous JavaScript and XML)이다. ajax는 자바스크립트를 이용해서 비동기적(asynchronous)으로 서버와 브라우저가 데이터를 교환할 수 있는 통신 방식을 의미한다.
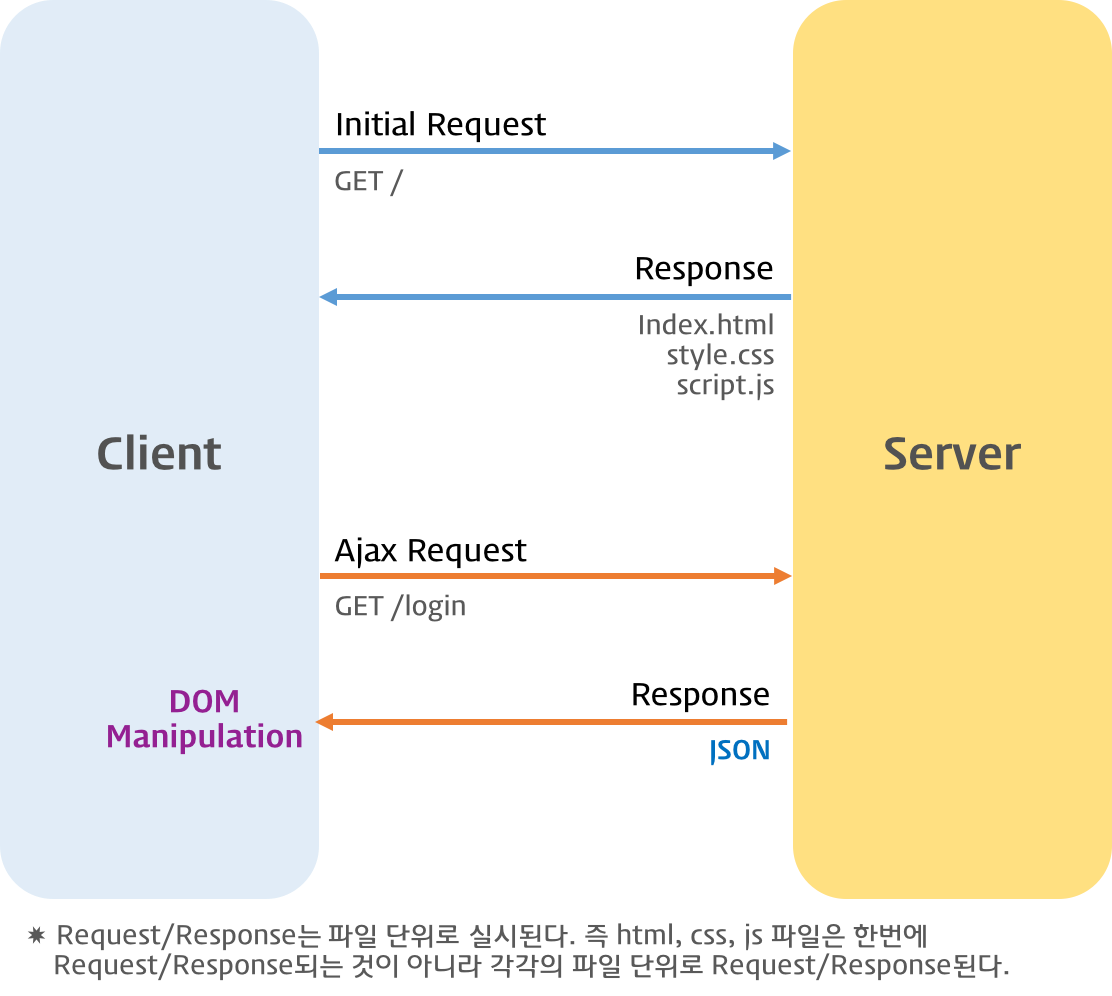
ajax lifecycle
서버로부터 웹페이지가 응답되면 화면 전체를 새롭게 렌더링해야 하는데 페이지 일부만 갱신하고도 동일한 효과를 볼 수 있도록 하는 것이 ajax이다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - ajax</title>
<link rel="stylesheet" href="css/style.css" />
<script type="module" src="js/index.js"></script>
</head>
<body>
<nav>
<ul id="navigation">
<li><a href="/">Home</a></li>
<li><a href="/service">Service</a></li>
<li><a href="/about">About</a></li>
</ul>
</nav>
<div id="root">Loading...</div>
</body>
</html>
위 예제를 살펴보면 link tag(<a href="/service">Service</a> 등)의 href 어트리뷰트에 path를 사용하고 있다. 따라서 내비게이션이 클릭되면 path가 추가된 URL이 서버로 요청된다. 하지만 ajax 방식은 내비게이션 클릭 이벤트를 캐치하고 preventDefault 메서드를 사용해 서버로의 요청을 방지한다. 이후, href 어트리뷰트에 path을 사용하여 ajax 요청을 하는 방식이다.
그리고 div.#root 요소에 웹페이지의 내용이 비어있는 것을 알 수 있다. 요청된 리소스(html, json 등)가 응답되면 클라이언트에서 div#root 요소에 응답받은 데이터를 기반으로 html을 생성해 추가한다.
이를 통해 불필요한 리소스의 중복 요청을 방지할 수 있다. 또한 페이지 전체를 리렌더링할 필요없이 갱신이 필요한 일부만 갱신하면 되므로 빠른 퍼포먼스와 부드러운 화면 표시 효과를 기대할 수 있어 새로고침이 없는 보다 향상된 사용자 경험을 구현할 수 있다는 장점이 있다.
JavaScript의 구현은 다음과 같다.
// index.js
import { Home, Service, About, NotFound } from './components.js';
const $root = document.getElementById('root');
const $navigation = document.getElementById('navigation');
const routes = [
{ path: '/', component: Home },
{ path: '/service', component: Service },
{ path: '/about', component: About },
];
const render = async path => {
try {
const component = routes.find(route => route.path === path)?.component || NotFound;
$root.replaceChildren(await component());
} catch (err) {
console.error(err);
}
};
// TODO: ajax 요청은 주소창의 url을 변경시키지 않으므로 history 관리가 되지 않는다.
$navigation.onclick = e => {
if (!e.target.matches('#navigation > li > a')) return;
e.preventDefault();
const path = e.target.getAttribute('href');
render(path);
};
// TODO: 주소창의 url이 변경되지 않기 때문에 새로고침 시 현재 렌더링된 페이지가 아닌 루트 페이지가 요청된다.
window.addEventListener('DOMContentLoaded', () => render('/'));
// components.js
const createElement = domString => {
const $temp = document.createElement('template');
$temp.innerHTML = domString;
return $temp.content;
};
const fetchData = async url => {
const res = await fetch(url);
const json = await res.json();
return json;
};
export const Home = async () => {
const { title, content } = await fetchData('/api/home');
return createElement(`<h1>${title}</h1><p>${content}</p>`);
};
export const Service = async () => {
const { title, content } = await fetchData('/api/service');
return createElement(`<h1>${title}</h1><p>${content}</p>`);
};
export const About = async () => {
const { title, content } = await fetchData('/api/about');
return createElement(`<h1>${title}</h1><p>${content}</p>`);
};
export const NotFound = () => createElement('<h1>404 NotFound</p>');
ajax 요청은 주소창의 URL을 변경시키지 않는다. 이는 브라우저의 뒤로가기, 앞으로가기 등의 history 관리가 동작하지 않음을 의미한다. 따라서 history.back(), history.go(n) 등도 동작하지 않는다. 주소창의 URL이 변경되지 않기 때문에 새로고침을 해도 언제나 첫페이지가 다시 로딩된다. 동일한 하나의 URL로 동작하는 ajax 방식은 SEO 이슈에서도 자유로울 수 없다.
위 예제를 실행하려면 다음 명령을 실행한다.
$ npm run ajax
3.3 Hash 방식
ajax 방식은 불필요한 리소스 중복 요청을 방지할 수 있고 새로고침이 없는 사용자 경험을 구현할 수 있다는 장점이 있지만 history 관리가 되지 않는 단점이 있다. 이를 보완한 방법이 Hash 방식이다.
Hash 방식은 URI의 fragment identifier(#service)의 고유 기능인 앵커(anchor)를 사용한다. fragment identifier는 hash mark 또는 hash라고 부르기도 한다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - Hash</title>
<link rel="stylesheet" href="css/style.css" />
<script type="module" src="js/index.js"></script>
</head>
<body>
<nav>
<ul>
<li><a href="#">Home</a></li>
<li><a href="#service">Service</a></li>
<li><a href="#about">About</a></li>
</ul>
</nav>
<div id="root">Loading...</div>
</body>
</html>
위 예제를 살펴보면 link tag(<a href="#service">Service</a> 등)의 href 어트리뷰트에 hash를 사용하고 있다. 즉, 내비게이션이 클릭되면 hash가 추가된 URI가 주소창에 표시된다. 단, URL이 동일한 상태에서 hash만 변경되면 브라우저는 서버에 어떠한 요청도 하지 않는다. 즉, URL의 hash는 변경되어도 서버에 새로운 요청을 보내지 않으며 따라서 페이지가 갱신되지 않는다. hash는 요청을 위한 것이 아니라 fragment identifier(#service)의 고유 기능인 앵커(anchor)로 웹페이지 내부에서 이동을 위한 것이기 때문이다.
또한 hash 방식은 서버에 새로운 요청을 보내지 않으며 따라서 페이지가 갱신되지 않지만 페이지마다 고유의 논리적 URL이 존재하므로 history 관리에 아무런 문제가 없다.
JavaScript의 구현은 다음과 같다.
// index.js
// components.js는 위와 동일하다.
import { Home, Service, About, NotFound } from './components.js';
const $root = document.getElementById('root');
const routes = [
{ path: '', component: Home },
{ path: 'service', component: Service },
{ path: 'about', component: About },
];
const render = async () => {
try {
// url의 hash를 취득
const hash = window.location.hash.replace('#', '');
const component = routes.find(route => route.path === hash)?.component || NotFound;
$root.replaceChildren(await component());
} catch (err) {
console.error(err);
}
};
// 네비게이션을 클릭하면 url의 hash가 변경되기 때문에 history 관리가 가능하다.
// 단, url의 hash만 변경되면 서버로 요청은 수행하지 않는다.
// url의 hash가 변경하면 발생하는 이벤트인 hashchange 이벤트를 사용하여 hash의 변경을 감지하여 필요한 ajax 요청을 수행한다.
// hash 방식의 단점은 url에 /#foo와 같은 해시뱅(HashBang)이 들어간다는 것이다.
window.addEventListener('hashchange', render);
// 새로고침을 하면 DOMContentLoaded 이벤트가 발생하고
// render 함수는 url의 hash를 취득해 새로고침 직전에 렌더링되었던 페이지를 다시 렌더링한다.
window.addEventListener('DOMContentLoaded', render);
hash 방식은 url의 hash가 변경하면 발생하는 이벤트인 hashchange 이벤트를 사용해 hash의 변경을 감지하고 url의 hash를 취득해 필요한 ajax 요청을 수행한다.
hash 방식의 단점은 url에 불필요한 #이 들어간다는 것이다. 일반적으로 hash 방식을 사용할 때 #!을 사용하기도 하는데 이를 해시뱅(Hash-bang)이라고 부른다.
hash 방식은 과도기적 기술이다. HTML5의 History API인 pushState가 모든 브라우저에서 지원이 된다면 해시뱅은 사용하지 않아도 되지만 현재 pushState는 일부의 브라우저(IE 10 이상)에서만 지원이 가능하다.
또 다른 문제는 SEO 이슈이다. 웹 크롤러는 검색 엔진이 웹사이트의 콘텐츠를 수집하기 위해 HTTP와 URL 스펙(RFC-2396같은)을 따른다. 이러한 크롤러는 JavaScript를 실행시키지 않기 때문에 hash 방식으로 만들어진 사이트의 콘텐츠를 수집할 수 없다. 구글은 해시뱅을 일반적인 URL로 변경시켜 이 문제를 해결한 것으로 알려져 있지만 다른 검색 엔진은 hash 방식으로 만들어진 사이트의 콘텐츠를 수집할 수 없을 수도 있다.
위 예제를 실행하려면 다음 명령을 실행한다.
$ npm run hash
3.4 pjax 방식
hash 방식의 가장 큰 단점은 SEO 이슈이다. 이를 보완한 방법이 HTML5의 History API인 pushState와 popstate 이벤트를 사용한 pjax(pushState + ajax) 방식이다. pushState와 popstate은 IE 10 이상에서 동작한다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - pjax</title>
<link rel="stylesheet" href="css/style.css" />
<script defer src="js/index.js"></script>
</head>
<body>
<nav>
<ul id="navigation">
<li><a href="/">Home</a></li>
<li><a href="/service">Service</a></li>
<li><a href="/about">About</a></li>
</ul>
</nav>
<div id="root">Loading...</div>
</body>
</html>
위 예제를 살펴보면 link tag(<a href="/service">Service</a> 등)의 href 어트리뷰트에 path를 사용하고 있다. 따라서 내비게이션이 클릭되면 path가 추가된 URL이 서버로 요청된다. 하지만 pjax 방식은 내비게이션 클릭 이벤트를 캐치하고 preventDefault 메서드를 사용해 서버로의 요청을 방지한다. 이후, href 어트리뷰트에 path을 사용하여 ajax 요청을 하는 방식이다.
이때 ajax 요청은 브라우저 주소창의 URL을 변경시키지 않아 history 관리가 불가능하다. 이때 사용하는 것이 pushState 메서드이다. pushState 메서드는 주소창의 URL을 변경하고 URL을 history entry로 추가하지만 서버로 HTTP 요청을 하지는 않는다.
JavaScript의 구현은 다음과 같다.
// index.js
// components.js는 위와 동일하다.
import { Home, Service, About, NotFound } from './components.js';
const $root = document.getElementById('root');
const $navigation = document.getElementById('navigation');
const routes = [
{ path: '/', component: Home },
{ path: '/service', component: Service },
{ path: '/about', component: About },
];
// TODO: path를 상태로 관리
const render = async path => {
// $navigation의 a 요소를 클릭하면 path(a 요소의 href)가 전달된다.
// 하지만 웹페이지가 처음 로딩되거나 앞으로/뒤로 가기 버튼을 클릭하면 path를 전달하지 않는다.
// 이때 window.location.pathname를 키로 routes에서 컴포넌트를 결정해 뷰를 전환한다.
const _path = path ?? window.location.pathname;
try {
const component = routes.find(route => route.path === _path)?.component || NotFound;
$root.replaceChildren(await component());
} catch (err) {
console.error(err);
}
};
$navigation.addEventListener('click', e => {
if (!e.target.matches('#navigation > li > a')) return;
/**
* 네비게이션을 클릭하면 주소창의 url이 변경되므로 HTTP 요청이 서버로 전송된다.
* preventDefault를 사용하여 이를 방지하고 history 관리를 위한 처리를 실행한다.
*/
e.preventDefault();
// 이동할 페이지의 path
const path = e.target.getAttribute('href');
// 현재 페이지와 이동할 페이지가 같으면 이동하지 않는다.
if (window.location.pathname === path) return;
// pushState는 주소창의 url을 변경하지만 HTTP 요청을 서버로 전송하지는 않는다.
window.history.pushState(null, null, path);
render(path);
});
/**
* pjax 방식은 hash를 사용하지 않으므로 hashchange 이벤트를 사용할 수 없다.
* popstate 이벤트는 pushState에 의해 발생하지 않고 앞으로/뒤로 가기 버튼을 클릭하거나
* history.forward/back/go(n)에 의해 history entry가 변경되면 발생한다.
* 앞으로/뒤로 가기 버튼을 클릭하면 window.location.pathname를 참조해 뷰를 전환한다.
*/
window.addEventListener('popstate', () => {
console.log('[popstate]', window.location.pathname);
render();
});
/**
* 웹페이지가 처음 로딩되면 window.location.pathname를 확인해 페이지를 이동시킨다.
* 새로고침을 클릭하면 현 페이지(예를 들어 localhost:5004/service)가 서버에 요청된다.
* 이에 응답하는 처리는 서버에서 구현해야 한다.
*/
window.addEventListener('DOMContentLoaded', () => {
render();
});
pjax 방식에서 사용하는 history.pushState 메서드는 주소창의 url을 변경하지만 HTTP 요청을 서버로 전송하지는 않는다. 따라서 페이지가 갱신되지 않는다. 하지만 페이지마다 고유의 URL이 존재하므로 history 관리에 아무런 문제가 없다. 또한 hash를 사용하지 않으므로 SEO에도 문제가 없다.
단, 브라우저의 새로고침 버튼을 클릭하면 브라우저 주소창의 url이 변경되지 않는 ajax 방식과 해시(fragment identifier)만 추가되는 hash 방식은 서버에 별도의 요청을 보내지 않지만 pjax 방식은 브라우저 주소창의 url이 변경되기 때문에 요청(예를 들어 localhost:5004/service)이 서버로 전달된다. 즉, pjax 방식은 서버 렌더링 방식과 ajax 방식이 혼재되어 있는 방식으로 서버의 지원이 필요하다. 이에 대한 서버 구현은 다음과 같다.
const express = require('express');
const path = require('path');
const app = express();
const port = 5004;
app.use(express.static(path.join(__dirname, 'public')));
app.get('/api/:page', (req, res) => {
const { page } = req.params;
res.sendFile(path.join(__dirname, `/data/${page}.json`));
});
// 브라우저 새로고침을 위한 처리 (다른 route가 존재하는 경우 맨 아래에 위치해야 한다)
// 브라우저 새로고침 시 서버는 index.html을 전달하고 클라이언트는 window.location.pathname를 참조해 다시 라우팅한다.
app.get('*', (req, res) => {
res.sendFile(path.join(__dirname, 'public/index.html'));
});
app.listen(port, () => {
console.log(`Server listening on http:/localhost:${port}`);
});
pjax 방식의 예제를 실행하려면 다음 명령을 실행한다.
$ npm run pjax
4. Conclusion
전통적 링크 방식에서 pjax 방식까지 SPA의 발전 과정을 살펴보았다. 지금까지 살펴본 4가지 방식을 History 관리, SEO 대응, 사용자 경험 등의 관점에서 정리하면 다음과 같다.
| 구분 | History 관리 | SEO 대응 | 사용자 경험 | 서버 렌더링 | 구현 난이도 | IE 대응 |
|---|---|---|---|---|---|---|
| 전통적 링크 방식 | ◯ | ◯ | ✗ | ◯ | 간단 | |
| ajax 방식 | ✗ | ✗ | ◯ | ✗ | 보통 | 7 이상 |
| hash 방식 | ◯ | ✗ | ◯ | ✗ | 보통 | 8 이상 |
| pjax 방식 | ◯ | ◯ | ◯ | △ | 복잡 | 10 이상 |
모든 소프트웨어 아키텍처에는 트레이드오프(trade-off)가 존재한다. SPA 또한 모든 애플리케이션에 적합한 은탄환(Silver bullet)은 아니다. 애플리케이션의 상황을 고려하여 적절한 방법을 선택할 필요가 있다.